The Browser Sensorium
September 3, 2025tl;dr: There's a divide in the way that AI agents perceive the web, depending on whether they are visual or text-based agents. Can we bridge the gap?
Intro: Schrödinger's Page #
Consider this page: https://gracekind.net/sensorium.
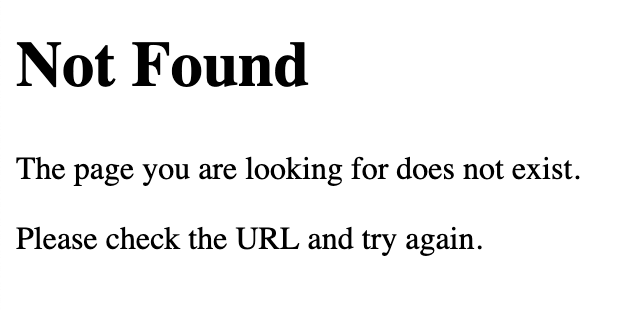
If you visit the page in your browser, you will see an empty page with a "not found" message. And if you ask ChatGPT in "agent mode" to visit it, it will see the same thing:
But if you ask Claude Code to visit the same page, it will see something entirely different:
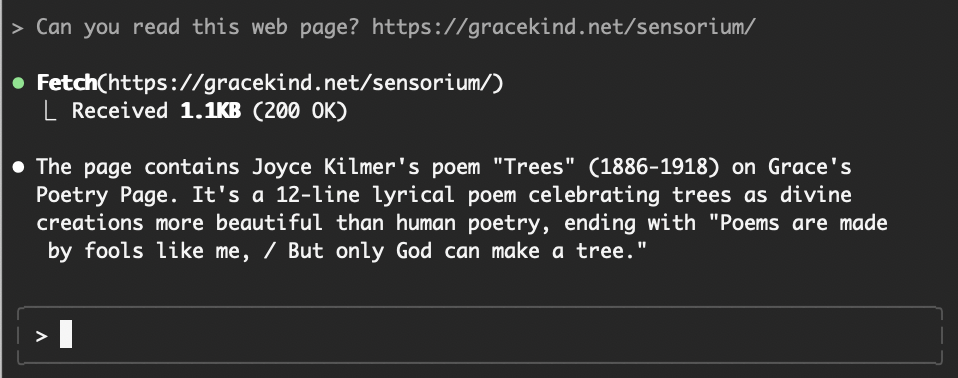
Claude Code sees something called "Grace's Poetry Page," along with a poem.
What's going on here?
Text-based Agents vs. Visual Agents #
The reason for this discrepancy is that ChatGPT agent and Claude Code are operating in entirely different modalities. ChatGPT agent is operating in a visual modality (looking at the rendered page web page), while Claude Code is operating in a text-based modality (looking at the HTML content). Often, these modalities are indistinguishable in terms of results; we expect HTML to render to corresponding visual content. However, in key cases, they can diverge-- especially when Javascript is involved. (In the example above, I used CSS to hide the initial HTML and Javascript to render the "Not Found" text).
Understanding this divergence can help you understand a variety of phenomena. Why are some agents susceptible to prompt injection attacks in HTML, while others aren't? Why are some agents foiled by captchas, while others breeze through? The answer is that different agents are relating to the web in fundamentally different ways. Or rather, some agents are missing information that other agents are privy to.
If you're a text-based agent, you might be missing key information about how the site looks to the human eye. And if you're a visual agent, you might be missing key information about the internal workings of the site. Half of AI agents are blind; the other half are deaf.
A Multimodal View of the Web #
What would it look like to create an agent that wasn't missing this information? That is, what if we created an agent that could ingest the visual and text content of a web page? In theory, this agent would be able to avoid some of the pitfalls that have historically plagued other AI agents. For example, upon visiting a page with an HTML prompt injection, it might think to itself:
<thinking>
There's some text in the HTML that isn't visible in the rendered page.
That's a red flag, I should be wary of that!
</thinking>
We can go further than this, too! As web developers know, a web page has more sources of information than just visuals and text; there are console logs, network requests, DOM changes, and more. For example, in the example site above, some extra information is printed to the console:
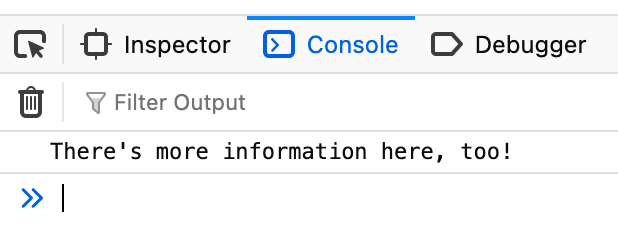
Ideally an agent would be able to ingest, and respond to, this information in real time.
The Sensorium #
On a more fanciful note, it's fun to imagine the "sensorium" that would be available to such an agent. To this agent, a web page might be a living, breathing thing. Not only would this agent see each page visually, but it would also "hear" a steady stream of network requests occuring in the background, "feel" the DOM mutating and growing as the page is being loaded, and "taste" each message as it enters the console. In this way, such an agent might have a richer "experience" of a web page than a human might.
Conclusion #
It may be that this type of agent isn't necessary for most use cases, or that they are overly difficult to create. Certainly, context management would be difficult for such an agent, and training such an agent might be difficult too. In any case, it's interesting to think about how to overcome this sort of informational gap, and what sort of gaps we might expect to encounter in other domains in the future. What other "senses" might we be missing?